Imagine a model that works flawlessly today and stumbles tomorrow, even though your data, pipeline, and logic remain unchanged. The culprit often hides in plain sight: how your input is tokenized. Every text input gets converted into token IDs before processing, and seemingly trivial formatting differences—spaces, line breaks, punctuation—can lead to vastly different token sequences. This is tokenization drift: a quiet shift in token space that causes unpredictable model behavior. In this listicle, we uncover seven key insights about this phenomenon and offer actionable fixes to keep your prompts consistent and reliable.
1. Tokenization Drift Defined
Tokenization drift occurs when minor surface-level changes in your input text—such as adding a space, changing a line break, or using different punctuation—result in entirely different token ID sequences. Because models rely on these token IDs to process language, even a small drift can push your input into a different region of token space, leading to unpredictable shifts in output. This is not a bug in your pipeline; it is an inherent property of how tokenizers work. For example, the GPT-2 tokenizer treats classify and classify (with a leading space) as completely different tokens. As a result, a model can behave perfectly one moment and degrade the next, simply because of a formatting nuance you didn't notice.
2. Why Models Are Sensitive to Formatting
During instruction tuning, models learn not only the tasks themselves but also the structure in which tasks are presented—specific separators, prefixes, and formatting patterns. When your prompt deviates from these learned patterns, the model operates outside its training distribution. This doesn't cause confusion per se; rather, the model does its best on inputs it was never optimized to handle, often resulting in inconsistent or degraded performance. For instance, if your training data always used a colon after instructions but your prompt uses a dash, the tokenization will differ, triggering unexpected attention patterns. Understanding this sensitivity is the first step toward controlling tokenization drift.
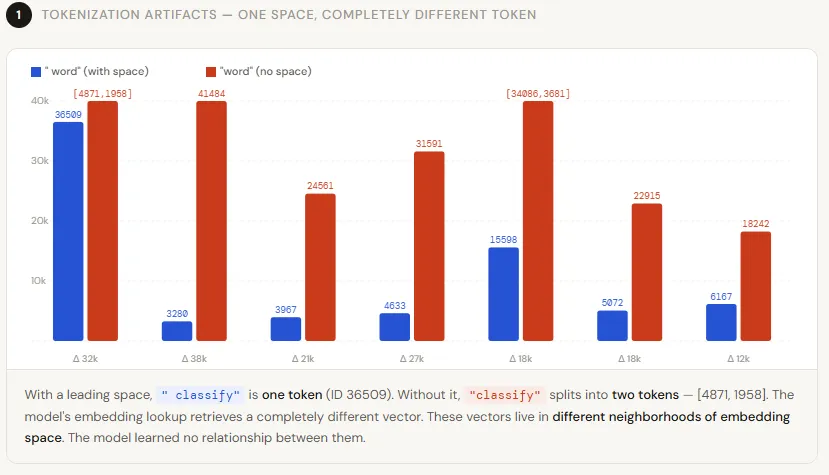
3. Real-World Example with GPT-2
To illustrate the artifact, consider the GPT-2 tokenizer—a Byte-Pair Encoding scheme used by GPT-4, LLaMA, and Mistral. Take seven common words and test each with and without a leading space. The results are striking: not a single pair produces the same token ID. More importantly, some words like classify without a space split into two tokens ([4871, 1958]), while classify remains a single token ([36509]). This means the model sees a different sequence length, shifting how attention is computed for everything that follows. This is a classic case of tokenization drift: a minor formatting change leading to a completely different internal representation.
4. Measuring Tokenization Drift with a Simple Metric
To quantify drift, we can build a lightweight metric. Using the same tokenizer, encode a prompt with various formatting options (e.g., with/without trailing newlines, different separators). Then, apply dimensionality reduction (like PCA) on the token embeddings to project them into a 2D space. The distance between these projected points serves as a drift score. Prompts that cluster tightly indicate stable tokenization, while scattered points reveal high drift. This metric helps you identify which formatting choices are most likely to cause unpredictable model behavior, allowing you to optimize your prompts before deployment.
5. Impact on Model Performance
Tokenization drift doesn't just change token IDs—it can alter entire attention patterns and output quality. For example, if your prompt for sentiment analysis uses a space after the colon ("Sentiment: positive") but your test samples omit it ("Sentiment:positive"), the model may produce an entirely different classification. This is because the token IDs for the colon and the space are different, and the positional encoding shifts. Over multiple prompts, small drifts accumulate, leading to inconsistent results that undermine trust in your model. Recognizing this impact is crucial for teams that rely on deterministic behavior from LLMs.
6. Practical Mitigation: Prompt Optimization Loop
One effective fix is a lightweight prompt optimization loop. Start by generating several variants of your prompt template (e.g., different spacing, line breaks, or punctuation). For each variant, compute the drift score using the metric from insight #4. Then, select the variant that minimizes drift while keeping the input readable. This loop can be automated: iterate over a grid of formatting options, measure drift, and pick the most stable one. Over time, you build a consistent format that aligns with the model's training distribution, reducing unexpected behavior.
7. Best Practices for Consistent Tokenization
To avoid tokenization drift in daily use, adopt these best practices: (a) Always use leading spaces before tokens that typically appear after separators, as many models expect this. (b) Stick to a single formatting style for separators, prefixes, and punctuation—don't mix colons with dashes. (c) Test tokenization before deployment by encoding sample prompts and comparing token IDs across slight variations. (d) Use a tokenizer-agnostic template if possible, such as enforcing consistent whitespace rules. By following these guidelines, you reduce the chance of drift and ensure more reliable model outputs.
Tokenization drift may be subtle, but its effects are far-reaching. By understanding the mechanisms behind it and applying these seven insights, you can take control of your prompt formatting and maintain consistent performance. Start auditing your tokenizer outputs today—your model will thank you.